This week, AI industry group MLCommons released a new set of results for AI performance. The new list, MLPerf Version 1.1, follows the first official set of benchmarks by five months and includes more than 1800 results from 20 organizations, with 350 measurements of energy efficiency. The majority of systems improved by between 5-30 percent from earlier this year, with some more than doubling their previous performance stats, according to MLCommons. The new results come on the heels of the announcement, last week, of a new machine-learning benchmark, called TCP-AIx.
In MLPerf’s inferencing benchmarks, systems made up of combinations of CPUs and GPUs or other accelerator chips are tested on up to six neural networks performing a variety of common functions—image classification, object detection, speech recognition, 3D medical imaging, natural language processing, and recommendation. For commercially available datacenter-based systems they were tested under two conditions—a simulation of real datacenter activity where queries arrive in bursts and «offline» activity where all the data is available at once. Computers meant to work onsite instead of in the data center—what MLPerf calls the edge—were measured in the offline state and as if they were receiving a single stream of data, such as from a security camera.
Although there were datacenter-class submissions from Dell, HPE, Inspur, Intel, LTech Korea, Lenovo, Nvidia, Neuchips, Qualcomm, and others, all but those from Qualcomm and Neuchips used Nvidia AI accelerator chips. Intel used no accelerator chip at all, instead demonstrating the performance of its CPUs alone. Neuchips only participated in the recommendation benchmark, as their accelerator, the RecAccel, is designed specifically to speed up recommender systems—which are used for recommending e-commerce items and for ranking search results.

MLPerf tests six common AIs under several conditions.NVIDIA
For the results Nvidia submitted itself, the company used software improvements alone to eke out as much as a 50 percent performance improvement over the past year. The systems tested were usually made up of one or two CPUs along with as many as eight accelerators. On a per-accelerator basis, systems with Nvidia A100 accelerators showed about double or more the performance those using the lower-power Nvidia A30. A30-based computers edged out systems based on Qualcomm’s Cloud AI 100 in four of six tests in the server scenario.
However, Qualcomm senior director of product management John Kehrli points out that his company’s accelerators were deliberately limited to a datacenter-friendly 75-watt power envelope per chip, but in the offline image recognition task they still managed to speed past some Nvidia A100-based computers with accelerators that had peak thermal designs of 400 W each.
Nvidia senior product manager for AI inferencing Dave Salvator pointed to two other outcomes for the company’s accelerators: First, for the first time Nvidia A100 accelerators were paired with server-class Arm CPUs instead of x86 CPUs. The results were nearly identical between Arm and x86 systems across all six benchmarks. «That’s an important milestone for Arm,» says Salvator. «It’s also a statement about the readiness of our software stack to be able to run the Arm architecture in a datacenter environment.»
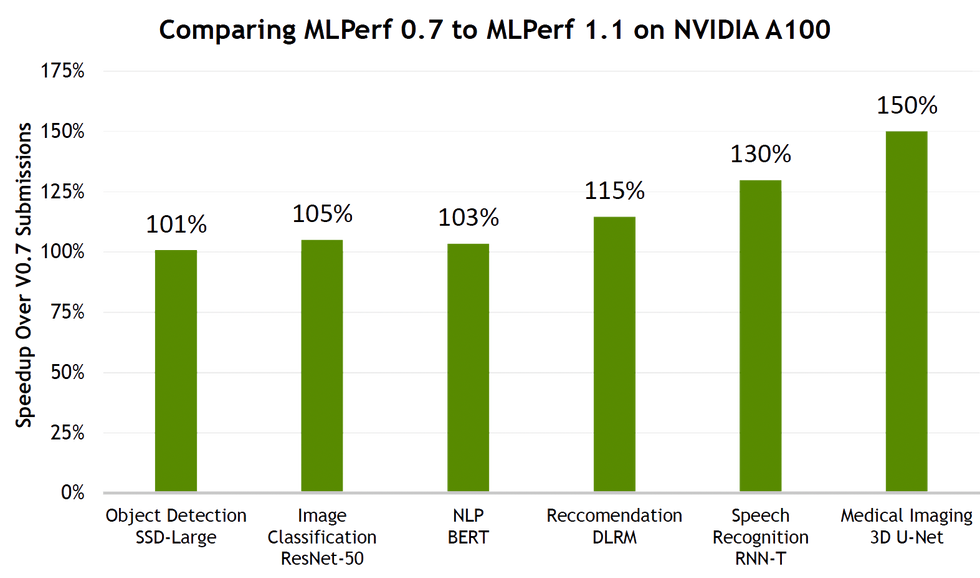
Nvidia has made gains in AI using only software improvements.NVIDIA
Separately from the formal MLPerf benchmarks, Nvidia showed off a new software technique called multi-instance GPU (MiG), which allows a single GPU to act as if it’s seven separate chips from the point of view of software. When the company ran all six benchmarks simultaneously plus an extra instance of object detection (just as a flex, I assume) the results were 95 percent of the single-instance value.
Nvidia A100-based systems also cleaned up on the edge server category, where systems are designed for places like stores and offices. These computers were tested along most of the same six benchmarks but with the recommender system swapped out for a low-res version of object detection. But in this category, there was a wider range of accelerators on offer, including Centaur’s AI Integrated Coprocessor; Qualcomm’s AI 100; Edgecortix’ DNA-F200 v2, Nvidia’s Jetson Xavier, and FuriosaAI’s Warboy.

Qualcomm topped the efficiency ranking for a machine vision test.Qualcomm
With six tests under two conditions each in two commercial categories using systems that vary in number of CPUs and accelerators, MLPerf performance results don’t really lend themselves to some kind of simple ordered list like Top500.org achieves with supercomputing. The parts that come closest are the efficiency tests, which can be boiled down to inferences per second per watt for the offline component. Qualcomm systems were tested for efficiency on object recognition, object detection, and natural language processing in both the datacenter and edge categories. In terms of inferences per second per watt, they beat the Nvidia-backed systems at the machine vision tests, but not on language processing. Nvidia-accelerated systems took all the rest of the spots.
In seeming opposition to MLPerf’s multidimensional nature, a new benchmark was introduced last week that aims for a single number. The Transaction Processing Performance Council says the TCP-Aix benchmark:
- Generates and processes large volumes of data
- Trains preprocessed data to produce realistic machine learning models
- Conducts accurate insights for real-world customer scenarios based on the generated models
- Can scale to large distributed configurations
- Allows for flexibility in configuration changes to meet the demands of the dynamic AI landscape.
The benchmark is meant to capture the complete end-to-end process of machine learning and AI, explains Hamesh Patel, chair of the TPCx-AI committee and principal engineer at Intel. That includes parts of the process that aren’t included in MLPerf such as preparing the data and optimization. «There was no benchmark that emulates an entire data science pipeline,» he says. «Customers have said it can take a week to prep [the data] and two days to train» a neural network.
Big differences between MLPerf and TPC-Aix include the latter’s dependence on synthetic data—data that resembles real data but is generated on the fly. MLPerf uses sets of real data for both training and inference, and MLCommons executive director David Kanter was skeptical about the value of results from synthetic data.
Membership among MLCommons and TPC has a lot of overlap, so it remains to be seen which if either of the two benchmarks gains over the other in credibility. MLPerf certainly has the advantage for the moment, and computer system makers are already being asked for MLPerf data as part of requests for proposals, at least two MLPerf participants report.
Source: IEEE Spectrum Computing